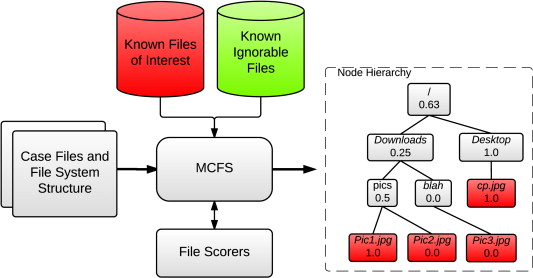
Monte Carlo - Digital Forensics on R@CMon
Janis Dalins from Faculty of IT is one of R@CMon's earliest users. We've previously blogged about some of his work at https://rcblog.erc.monash.edu.au/blog/2013/07/rcmon-accelerates-forensic-data-research-2/. Recently Janis (along with Campbell Wilson and Mark Carman, also from Monash's Faculty of IT) published their latest research assisted by R@CMon, Monte-Carlo Filesystem Search – A crawl strategy for digital forensics, in The International Journal of Digital Forensics & Incident Response.
The articles abstract provides a great overview:
Criminal investigations invariably involve the triage or cursory examination of relevant electronic media for evidentiary value. Legislative restrictions and operational considerations can result in investigators having minimal time and resources to establish such relevance, particularly in situations where a person is in custody and awaiting interview. Traditional uninformed search methods can be slow, and informed search techniques are very sensitive to the search heuristic's quality. This research introduces Monte-Carlo Filesystem Search, an efficient crawl strategy designed to assist investigators by identifying known materials of interest in minimum time, particularly in bandwidth constrained environments. This is achieved by leveraging random selection with non-binary scoring to ensure robustness. The algorithm is then expanded with the integration of domain knowledge. A rigorous and extensive training and testing regime conducted using electronic media seized during investigations into online child exploitation proves the efficacy of this approach.
In this research Janis et al pioneered Monte-Carlo Filesystem Search (MCFS), a specialised use of Monte-Carlo Tree Search (MCTS), a heuristic search technique commonly employed in game theory. This approach resulted in a high-efficacy (in terms of positive determination, speed, and low resource requirement) approach to classifying potential digital assets of interest in active criminal investigations.
Janis provided the following excellent feedback when we asked him how things were going:
Our project, “Monte Carlo Filesystem Search”, was proposed as a means for accelerating the process of digital forensics by identifying interesting files on suspect hard disk drives. We initially conducted tests on a simulated dataset (a laptop HDD containing simulated illegal photos and movies) hosted on an old server hosted here at FIT. Performance was slow (we were searching entire HDDs, after all!), and the mundane aspects of hosting (ensuring power, network connectivity etc) proved to be far more time consuming than I’d anticipated. We were extremely keen to use the Research Cloud when it became available, as we could spin up instances and conduct parallel tests without having to find rack space, power points, network connections, whitelist MAC addresses, and drive into campus at 1am because a machine had frozen.
Whilst cloud computing is an overused catchphrase (in my opinion), it makes sense for research such as mine. Whilst we couldn’t use shared infrastructure for our final round of tests for the paper (the dataset couldn’t leave the owner’s premises), we heavily exploited R@CMon as a means for testing and bedding down our approach before going onsite.
We’re back on R@CMon for new research (we’re using openly available data), and loving it. No more issues with physical access, hardware/network configuration. Hardware failure? Someone else’s problem, and with redundancy, probably not even noticed. Outages? Advertised in advance. I may need to run experiments a few more times in order to identify outliers caused by network congestion etc, but so what? I don’t need to be there, and I’ve got more than enough other work to get on with in the meantime.